Solving L1-Penalization of Kullback-Leibler Divergence using SMART Algorithm
Author: Tran Thu Le
Date: 7/3/2023
Abstract: In this note, we show how to modify the SMART-algorithm to solve the Sparse regression of Kullback-Leibler divergence using L1-pennalization.
Preliminaries
For vectors in a finite dimensional vector space, we denote by , , if and the vectors with operators applied elementwise. Here we set .
For , the negative entropy is a convex function defined by
where . Notice that .
The Bregman divergence of a convex function is
The Kullback-Leibler divergence (a.k.a. relative entropy) is the Bregman divergence of negative entropy
where and have the same signs, i.e. and for all .
One should have 2 remarks. First, KL div. has gradient of the form
This holds for any same sign vectors .
Second, the Bregman div. satisfies the following Cosine law
If we let for some given , we have
We call this the Bidual Bregman div. theorem.
Sparse-SMART algorithm
Simultaneous Multiplicative Algebraic Reconstruction Technique (SMART) is an iterative method to solve Kullback-Leibler divergence (KL div.) problem, see [1]. We now show how to use a modification of SMART, say Sparse-SMART, to solve the following sparse convex problem
where with , , . Note that , without the condition , the constraint should be explicitly declared.
This problem aims to solve the linear inverse problem using KL div as a distance between and and the optimal solution tends to be sparse due to the use of L1-norm. Note that by the non-negativity constraint , we have . Here, w.l.o.g we assume that
Under this assumption we have, see [Prop. 2, [1]]
Let we have
So for , we have
Then achieves its min value at being the solution of the following equation
Then
Let the residual of , the formula of can be rewritten
Explicitly, the Sparse-SMART update rule for our problem is as follows
Note. 1) If then the optimal solution is . So, in pratice we only consider . 2) In the formula remains valid if there are some indices with . In such cases, we should take into account the condition . 3) The classical SMART is
Numerical Experiment
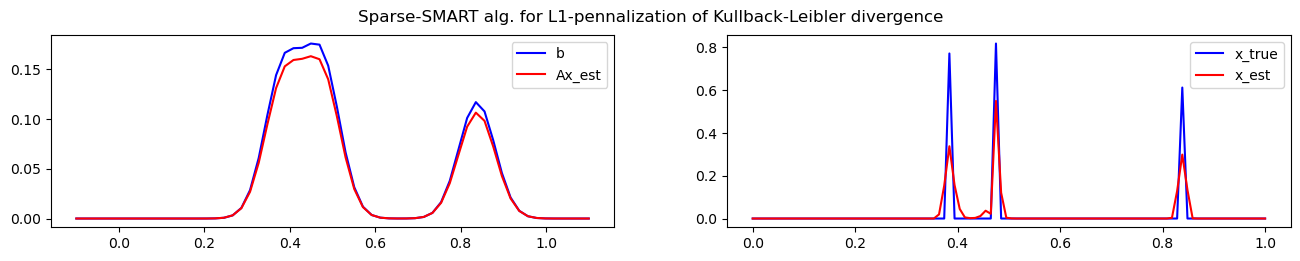
import numpy as np
import matplotlib.pyplot as plt
def dic(x, t, w):
# atoms with L1-norm normalization
diff = x.reshape(-1, 1) - t.reshape(1, -1)
gausses = 2**(-diff**2/w**2)
norms = np.linalg.norm(gausses, axis=0, ord=1)
assert gausses.shape[1] == len(norms)
return gausses/norms
def sparse_SMART(b, A, lbd, x_init, iter_stop=50):
x = x_init
x_list = [x]
for i in range(iter_stop):
Ax = A.dot(x)
r = - np.log(Ax/b)
x = x * np.exp( (A.T).dot( r ) - lbd)
x_list += [x]
return x_list
def run():
m, n = 60, 100
k=3
locs = np.linspace(-0.1, 1.1, m)
t = np.linspace(0., 1., n)
w = 0.05
A = dic(locs, t, w)
np.random.seed(1234)
rand_indices = np.random.choice(range(n), k)
x_true = np.zeros_like(t)
x_true[rand_indices] = np.random.rand(k)
b = A.dot(x_true)
lbd_max = np.max( (A.T).dot(b))
lbd = 0.5*lbd_max
x_init = np.random.rand(n)/20.
x_list = sparse_SMART(b, A, lbd, x_init, iter_stop=1000)
fig, axs = plt.subplots(1, 2, figsize=(16, 2.5))
ax=axs[0]
ax.plot(locs, b, color="blue", label="b")
ax.plot(locs, A.dot(x_list[-1]), color="red", label="Ax_est")
ax.legend()
ax=axs[1]
ax.plot(t, x_true, color="blue", label="x_true")
ax.plot(t, x_list[-1], color="red", label="x_est")
ax.legend()
fig.suptitle("Sparse-SMART alg. for L1-pennalization of Kullback-Leibler divergence")
plt.plot()
plt.show()
run()
Note. In this code, it is important to notice that we should normalize the dictionary using norm instead of usual norm. Second, the initialized vector should be small, but not zero, otherwise, the whole sequence will be zeros.
References
[1]: Petra, Stefania, et al. “B-SMART: Bregman-based first-order algorithms for non-negative compressed sensing problems.” Scale Space and Variational Methods in Computer Vision: 4th International Conference, SSVM 2013, Schloss Seggau, Leibnitz, Austria, June 2-6, 2013. Proceedings 4. Springer Berlin Heidelberg, 2013.







