Solving Elastic-Net problem using Proximal Gradient Descent
The Python code of this post is available on my Github.
Problem definition
In this note, we consider the so-called Elastic-Net problem
x∈Rnmin21∣∣b−Ax∣∣22+λ1∣∣x∣∣1+2λ2∣∣x∣∣22
where b∈Rm and A∈Rm×n, λ1,λ2≥0. The optimal solution to this problem is sparse if λ2 is small. In particular, the Lasso problem corresponds to λ2=0.
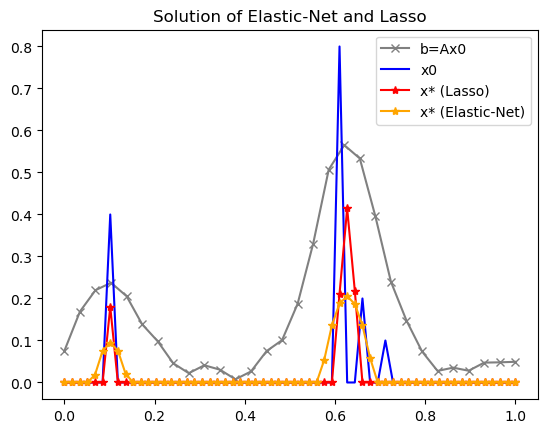
The following figures demonstrate the difference between the solutions of the Lasso and Elastic-Net problems. As you can see, the solution obtained through Lasso is sparser, while the solution obtained through Elastic-Net is smoother.
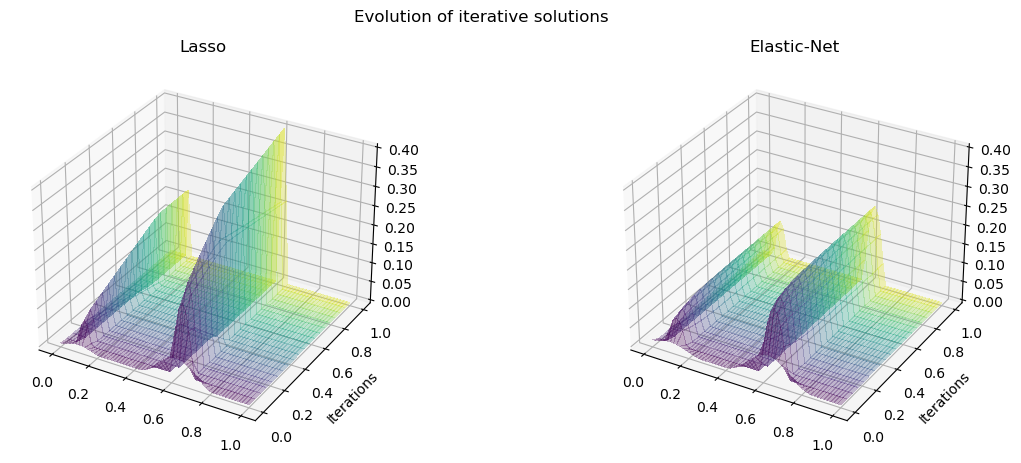
The evolution of iterative solutions of the two problems is
Solving method using Proximal Gradient Descent
The proximal gradient method is the following updating rule
x(k+1)=proxg/α(x(k)−α1∇f(x(k)))
Here α>0 is the Lipschitz constant of the gradient of f (assuming that it exists), in this case f is said to be α-smooth.
Here let’s explain how such above update is a convergence algorithm.
Note that the Elastic-Net problem is a special case of the more general form
xminP(x)=f(x)+g(x)
where f is the main smooth loss function and g is a regularization function which is usually non-smooth. If one assumes that f has α-Lipschitz continuous gradient then
P(x′)≤f(x)+⟨∇f(x),x′−x⟩+2α∣∣x′−x∣∣22+g(x′)=M(x′)
The function M is called the surrogate function of P with equality if x′=x. To minimize P we can minimize M, this is known as the Majorize-Minimization method. To do that, let us rewrite M,
M(x′)=f(x)−2α1∣∣∇f(x)∣∣22+2α∣∣x′−x+α1∇f(x)∣∣22+g(x′)
Then, to minimize M we apply the proximal operator on g/α with argument x+, where x+=x−α1∇f(x) is the gradient descent update from x, i.e.
argx′min21∣∣x′−x+∣∣22+α1g(x′)=proxg/α(x+).
This is exactly the proximal gradient descent method described above.
Back to Elastic-Net problem
To apply the proximal gradient descent, we need the closed form expressions for α, ∇f and proxg/α. This is a simple task.
For the Elastic-Net problem, we can choose α=∣∣A∣∣Fro2=∑i+1n∣∣ai∣∣22 the squared Frobenius norm, i.e. the total squared norms of the i-th column ai of A.
With f(x)=21∣∣b−Ax∣∣22, we have ∇f(x)=−AT(b−Ax).
For g(x)=λ1∣∣x∣∣1+2λ2∣∣x∣∣22, we find the proximal associated with g/α as follows.
argx′min21∣∣x′−x+∣∣22+αλ1∣∣x′∣∣1+2αλ2∣∣x′∣∣22
Let s=sign(x′), then the Fermat’s rule reads as follows
x′−x++αλ1s+αλ2x′=0↔x′=α+λ2α[x+−αλ1s]
By considering different cases of sign of x′ and x+±αλ1, we can eliminate s in the formula of x′ as follows
proxg/α(x+)=x′=α+λ2αsign(x+)[∣x+∣−αλ1]+.
This is the closed form expression for proximal of g/α.







