A deep understanding of PCA: From statistics to optimization explanation
Abstract. Principal Component Analysis (PCA) stands as a widely utilized technique for condensing high-dimensional data into a low-dimensional space while retaining the “maximum amount of information”. This post delves into the mathematical modeling of PCA through the lens of optimization rather than the other popular explanations based on statistics.
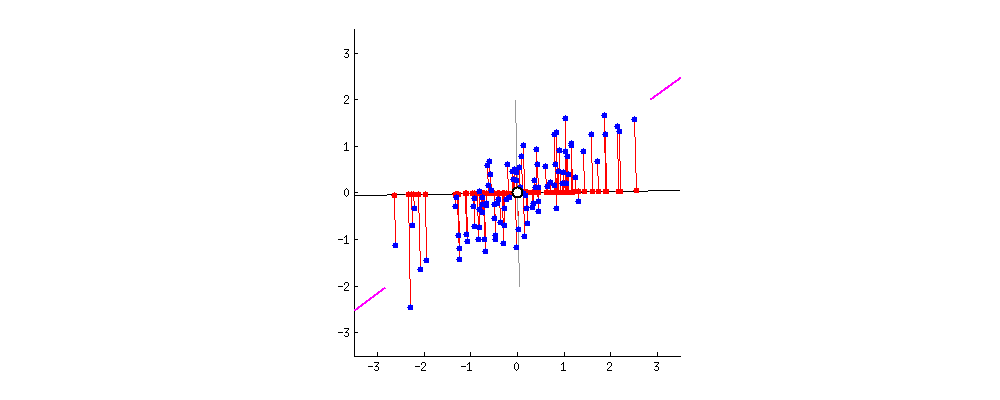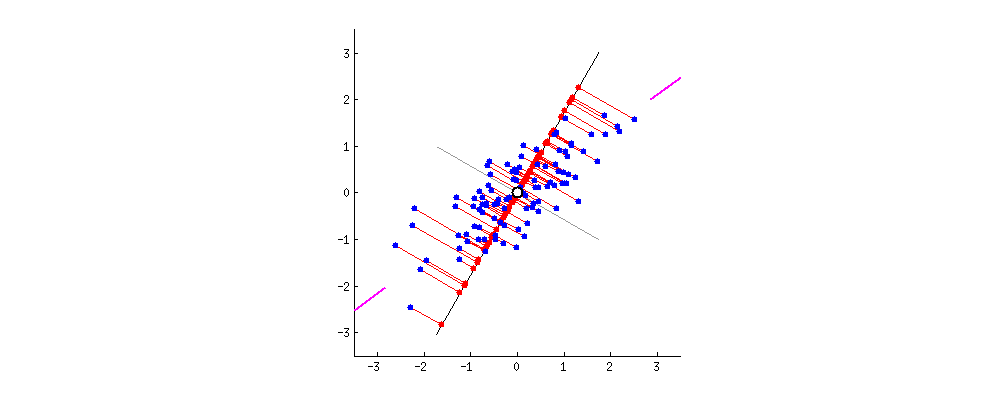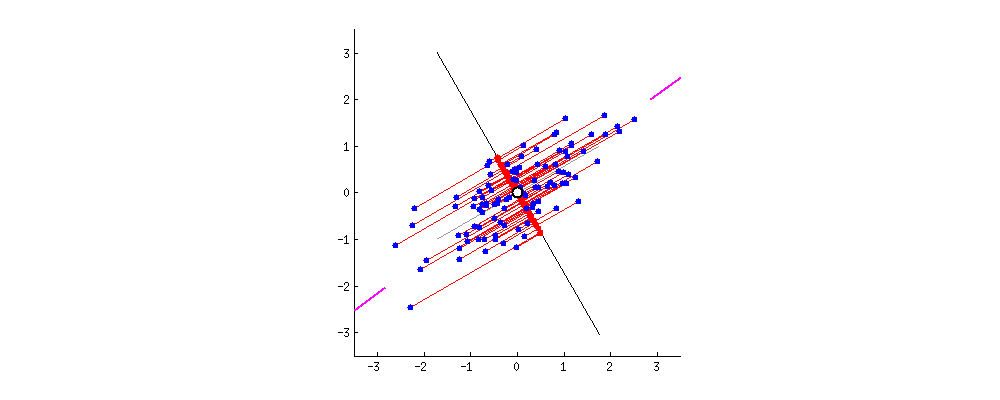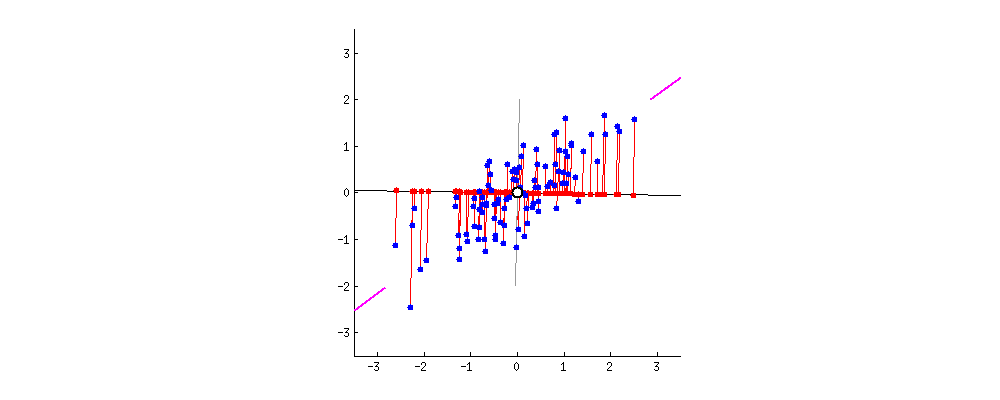
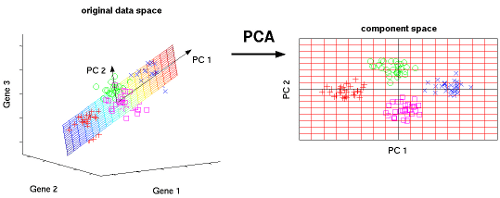
1. Introduction
Principal Component Analysis (PCA) stands out as a widely embraced technique for transforming very high-dimensional datasets into a very low dimension while retaining the “maximum amount of information”, see the figures above, depicting the transformation from 2D to 1D [1] and 3D to 2D [2].
The post is structured as follows:
- The next section provides a brief explanation of PCA from a statistical perspective.
- Following that, we delve into the optimization approach to explain PCA, emphasizing its central theme in this post.
- The post concludes by offering insights through comments that draw connections between the two approaches.
2. Statistics approach
In statistical terms, PCA method involves transforming the original variables into a new set of uncorrelated variables known as principal components. In order to maximize the information in the low-dimensional space, these components represent linear combinations of the original variables and are arranged in a specific order: the first principal component (to the eigenvector associated with the largest eigenvalue of the covariance matrix) explains the maximum variance in the data, the second component (the eigenvector associated with the second largest eigenvalue) explains the maximum remaining variance orthogonal to the first, and so forth.
While this statistical explanation for PCA is simple, it masks the intricate relationships among the concepts of eigenvectors, eigenvalues, the covariance matrix, and the covariance matrix’s role in maximum information preservation.
To unravel these complexities, in the following section, we will employ an optimization approach to describe how the PCA method works and thus provide a profound understanding of PCA.
3. Optimization approach
Given data points in a high dimensional space (large ). The goal of PCA is to represent these points using other points in a very low dimensional space () spanned by , i.e.
where and . Here we assume that forms an orthogonal setting, i.e.
Here, the approximation needs to be defined in a manner that ensures the preservation of the “maximum amount of information.” Intuitively, this preservation can be achieved through a “regression” model, wherein we seek the hyperplane that best fits the data points . In this context, represents the projection of onto the hyperplane (refer to the figures above).
Let’s delve into the mathematical details. PCA is essentially equivalent to solving the following optimization regression problem [3]:
The hard part of this problem is finding since it is relatively easy to find and according to the following formulas (see more details in [3]):
and
Note that w.l.o.g. we may assume that (otherwise, we let ). By the formula of , the problem (1) now can be rewritten as follows:
Expanding (2), the focus now is to maximize
where and is a (scaled) covariance matrix.
The problem of finding is now equivalent to
Let us now focus a particular case of (3) when i.e. :
The minimum value of this problem is the so-called “norm of operator” of , which is exactly the maximum eigenvalue of , see e.g. [4], while the minimizer is the corresponding eigenvector.
In general, let , where a unit orthogonal matrix of eigenvectors, i.e. , and be the diagonal matrix of eigenvalues of such that then optimal solution of (3) is
4. Conclusion
Through the lens of the optimization approach, it becomes evident that PCA can be conceptualized as a regression model. In this model, the high-dimensional data points , are aptly represented by a lower-dimensional points , through a linear relation , where .
In other words, the aim of preserving the “maximum amount of information” of data points can be achieved by solving a regression model.
In this model, the optimal matrix is found to be constructed using the largest eigenvalues and their corresponding eigenvectors from the (scaled) covariance matrix of . This connection unveils itself as a generalization of the well-known fact: the “norm of a (positive definite) matrix is the largest eigenvalue of that matrix.”
5. References
[1] step-step-explanation-principal-component-analysis
[2] explanation-of-principal-component-analysis
[3] PCA and LASSO
[4] operator-norm-is-equal-to-max-eigenvalue







